Numerical representation
The choice of a basis still posed some problems for axiomatic medieval scholars.
For example, the representation of 1/3 = 0.3333… could never be exact in decimal notation. If fractions (rational numbers) have a periodical decimal sequence, real numbers like
| √ 2= 1.414213562373… |
It was only at the end of the XIX century, with G. Cantor, that real numbers were defined as (equivalence classes of) Cauchy sequences of rational numbers, where the sequence:
| x0=1, x1=1.4, x2=1.41, x3=1.414, x4=1.4142, ... |
This interpretation of Cantor represented a great conceptual advance, allowing further to distinguish countable infinity from continuous infinity.
It is clear that the choice of the decimal basis for a real number
representative is just the most common choice from an uncountable
number of other possibilities.
Already in the XVII century,
Leibniz
advocated advantages in binary representation − which
is adopted nowadays in internal computer routines.
In general we can use any natural base β > 1, to write
a real number.
For instance, in Scientific Notation (usually β=10),
| x = ± (0. a1 a2 ... an ...)β × βt |
| = ± | ∞ ∑ k=1 | ak βt-k |
| 0.1 × β1 = 0.01 × β2 = 0.001 × β3 = 1 |
Note that, by convention, 0.999… is identified with the representation 1.000… (both sequences converge to 1).
Floating Point Representation
Definition: Floating Point System
The FP(β, n, t-, t+) system is the set of rational numbers
| FP(β, n, t-, t+) = {0} ∪ { ± 0. a1 a2 ... an × βt : ak∈ {0,..., β-1}, a1≠ 0, t∈ {t-, ..., t+ } } |
(i) Note that as a1 ≠ 0, zero must be represented separately (it might be a bit, a zero flag, as there is a bit that denotes the sign sign flag).
(ii) Usually β=10, but binary representation β=2 is preferred in computers (the digits ai might be 0 or 1). Details on computer implementation may be found in the link IEEE 754-1985 .
(iii) In programming languages (such as C, Fortran, Matlab) these FP systems are set when we declare the variables. Usually words like single, float, real*4,... stand for a single precision FP system with 4 bytes (23 bits − binary digits in the mantissa ~ up to 8 decimal digits). More recently it is standard to use double precision FP systems with 8 bytes (53 bits − binary digits in the mantissa ~ up to 16 decimal digits) and the variables are declared as double, float, real*8,...
Thus, we must map the real numbers to the rational number set FP,
| fl: R → FP(β, n, t-, t+) ⊂ Q |
- Finite exponent limitations (errors that may abort execution):
- Overflow: when the exponent t is greater than t+.
- Underflow: when the exponent t is less than t-.
- Finite mantissa limitations (errors that we will study):
- Rounding errors: truncation and rounding.
Rounding
| x = ± 0. a1 a2 ... an an+1 .... × βt |
- Truncation
flc(x) = ± 0. a1 a2 ... an × βt - Rounding (half-up) (note: β > 2 is even)
fls(x) = ± 0. a1' a2' ... an' × βt'
If an+1 > β/2 then the digits ai' and the exponent t' result from the representation of the sum
| 0. a1 a2 ... an × βt + βt − n. |
(i) We may also consider
| fls(x) = flc(x + 1/2 βt − n) |
Definition:
Consider x an exact value and x~ an approximated value of x, we define:
- Error : ex( x~ ) = x − x~
- Absolute error : |ex( x~ )| = |x − x~|
- Relative error (x ≠ 0): |δx( x~ )| with
δx( x~ ) = ex( x~ )
x
- We also use δx~ when it is more important to emphasize which is the approximation.
As in a FP system the rounding errors are inherent, we bound the rounding relative error |δarr(x)|, meaning
| δarr(x) = δx(fl(x)) = | x − fl(x) x |
Theorem:
For any x: fl(x)∈ FP(β, n), we have the relative error estimates:
- Truncation : |δarr(x) | < uc = β1-n
proof:
We prove for truncation. Consider any real number x
| x = ± 0.a1 ... an an+1 ... × βt |
| |x|≥ 0.1 × βt = βt − 1 |
| |earr| = |x − flc(x)| = |0.a1 ... an an+1... − 0.a1 ... an| × βt |
| = 0.0 ... 0 an+1... × βt ≤ 0.0 ... 1 0 ... × βt = βt − n |
| |δarr| = |earr|/|x| ≤ βt − n / βt − 1 = β1 − n |
Remark
Note that in a FP system we never round to zero.
In some calculator machines, or in some ill implemented FP systems, it is common to see an overflow error, but not an underflow error, meaning that small absolute values are improperly rounded to zero.
This leads to odd situations, like null values for exponentials... for instance,
| exp(-exp(8)) = 0.243… × 10-1294 |
- How to present the result, using a conventional machine?
In these cases you should separate calculations − what you need to compute from what is not representable. Thus, we may reduce to powers of 10, using logarithms, and presenting the result afterwards:
| e-exp(8) = 10-exp(8)/log(10) = 10-1294.6136 |
These type of errors may get worst while proceeding with further calculations... just note that if the result was 0 we could not get back the logarithm that should be -exp(8).
Error propagation in functions
| x~ ≈ x ⇒ f(x~ ) ≈ f(x), |
| ef(x) = f(x) − f(x~ ) = f '(ξ) (x-x~) = f '(ξ)ex |
It results (for x≠ 0, f(x)≠ 0)
| δf(x) = ef(x)/f(x) = | f '(ξ) f(x) | ex = | x f '(ξ) f(x) | δx |
| |δf(x) | ≤ | |x| maxξ∈ [x,x~] |f '(ξ)| |f(x)| | |δx| . |
In fact, neglecting the term o(ex) in
| f(x~ ) = f(x) + f '(x)ex + o(ex) |
| δf(x) ≈ | x f '(x) f(x) | δx |
Definition: The value Pf(x) = x f '(x)/f(x) is called the condition number of f in x, and we have
| δf(x) ≈ Pf(x) δx |
Examples:
- If f(x)=xp, we get Pf(x)=p, and therefore
δx^p ≈ p δx.
We conclude that for larger powers the initial relative error will be quite increased.
- If f(x)=ex, we get Pf(x)=x, thus
δexp(x) ≈ x δx.
We conclude that for large |x| elevado, the initial relative error will be quite increased.
- If f(x)=x-a, (a ≠ 0, constant) we get Pf(x)=x/(x-a),
and therefore δx-a = x/(x-a) δx.
We conclude that for x ≈ a, the initial relative error will be largely increased.
This example shows that the sum/subtraction may lead to significative perturbations on the calculations, due to} "subtractive cancellation".
- If f(x)=ax, (a ≠ 0, constant) we get Pf(x)=1, and therefore
δax = δx.
In this case the original error is not affected.
In these cases, a reasonable approximation of x may lead to an excellent result in terms of f(x).
Definition: We say that a function f is ill conditioned near a point z if, in the limit, |Pf(z)| = ∞.
Operations (functions with two or more variables)
In the case of two (or several) variables, we must consider simultaneous errors in both variables. Considering the Taylor expansion with two variables (∂m represents the partial derivative in the m-th variable):
| f(x~, y~) = f(x, y) + ∂1f(x, y)ex + ∂2f(x, y)ey + o(ex, ey) |
| δf(x,y) ≈ | x ∂1f(x,y) f(x,y) | δx + | y ∂2f(x,y) f(x,y) | δy |
| δf(x,y)≈ Pfx(x,y)δx + Pfy(x,y)δy |
- When any of these condition numbers tends to infinity in a value (x,y) then we say that there is ill conditioning of f near (x,y), as previously presented for a single variable.
- Likewise these notions are extended for functions with more than two variables.
- For the sum (subtraction) we get
δx+y = x
x+yδx + y
x+yδy ; δx − y = x
x − yδx − y
x − yδy
This formula shows immediately that there will be problems while subtracting similar quantities, i.e. x ≈ y, which is the case of subtractive cancellation, associated with significative rounding error propagation. - In the case of products (or divisions), the application of the formula gives
δxy ≈ δx + δy ; δx/y ≈ δx − δy δxy = δx + δy − δxδy
Error propagation in algorithms
Algorithm: While calculating z=f(x), we consider an algorithm as a mathematically equivalent form (but not numerically equivalent) defined by the finite composition of elementary functions Fk:
| z1=F1(x); z2=F2(x, z1); ... zn=Fn(x,...,zn-1); |
| such that z=zn . |
For instance, to calculate z=sin(x2)+x2, we may consider the algorithm
| z1=x2; z2 = sin(z1); z3 = z2+z1. |
Definition: In a FP(β,n) system we say that F is an elementary computational function associated to a function f, if
| F(y) = fl(f(y)), ∀ y∈ D ⊆ FP(β,n) |
| D = { x∈ FP(β,n) : x > 0 }. |
- In standard programming languages (C, Fortran, Matlab ...) the simplest
functions/operations are implemented to be elementary and they usually return
the exact value up to a rounding error in the 15th decimal place (in double
precision). For instances, we will consider as elementary:
- the functions: exp, log, sin, cos,
- the operations: + , − , * , / , ^ (sum, subtraction, product, division, power);
- In principle the admissible set D should be restricted to avoid
Overflow or Underflow errors.
For instance, if x=10q then in a system FP(10,n,-t,t) when we program the elementary operation x^p we should have an error when xp = 0.1 × 101+qp has a larger exponent than the one admissible by the system, for instance, for q > 0:- when p > (t-1)/q : an Overflow error message should occur,
- when p < -(t+1)/q : an Underflow error message should occur.
Condition numbers in an algorithm
- Condition numbers without rounding error
The linear approximation allows to establish a sequence between the partial results and the final result for the condition number.
We may establish this relation decomposing the function in successive compositions. It is then enough to show for a single composition to conclude the result for the whole sequence.
Let z=f(g(x)) that we decompose in z1 = g(x); z2 = f(z1).
Applying the formula at each step, we getδz2 ≈ z1 f '(z1)
f(z1)δz1 = g(x) f '(g(x))
f(g(x))δz1 ≈ g(x) f '(g(x))
f(g(x))x g'(x)
g(x)δx = x g'(x)f '(g(x))
f(g(x))δx = Pf ◦ g(x) δx
Proposition: With the linear approximation, without rounding errors, the composition of the condition numbers at each step equals the condition number of the whole composition.
- Condition numbers with rounding errors
Even with well implemented elementary functions, at each step we must consider a rounding error. Thus, to calculate the error propagation in the algorithm we should add a rounding error, at each step. For instance, in the first step:δz1≈ Pf(x)δx + δarr1
Example: Consider the hyperbolic sinus function,
| sinh(x)=(ex − e-x)/2 |
- z1 = exp (x);
- z2 = 1/z1;
- z3 = z2 − z1;
- z4 = z3/2;
- δz1 ≈ x δx + δarr1;
- δz2 ≈ − δz1 +δarr2;
- δz3 ≈ z1/(z1-z2)δz1 − z2/(z1-z2) δz2 +δarr3;
- δz4 ≈ δz3 +δarr4;
- δz2 ≈ − (x δx + δarr1) + δarr2;
-
δz3 ≈ ex/(ex-e-x)δz1 − e-x/(ex-e-x)δz2 + δarr3 ≈ ex/(ex-e-x)(x δx + δarr1) − e-x/(ex-e-x) (- x δx -δarr1 + δarr2) + δarr3 = x(ex+e-x)/(ex-e-x)δx+(ex+e-x)/(ex-e-x) δarr1 − e-x/(ex-e-x)δarr2 + δarr3; -
δz4 ≈ x(ex+e-x)/(ex-e-x)δx +(ex+e-x)/(ex-e-x)δarr1 − e-x/(ex-e-x)δarr2 +δarr3+δarr4;
| δz4 ≈ Pf(x) δx + Q1(x)δarr1 + Q2(x)δarr2 + Q3(x)δarr3 + Q4(x)δarr4 |
Remark: In fact, we may simplify the increasing sequence of calculations to obtain δz4 considering from the start that δx=0.
This way, we just calculate the terms Qk(x) as the terms Pf(x) are given by the explicit formula.
It is an exercise to repeat the previous steps in this simpler fashion:
δz1 ≈ x δx + δarr1 = δarr1;
δz2 ≈ -δz1 +δarr2 = -δarr1 +δarr2;
δz3 ≈ ( (ex + e-x)δarr1 − e-xδarr2 ) /(ex-e-x) + δarr3;
δz4 ≈ δz3 +δarr4;
and the coefficients are exactly the same!
- Note that sinh is not ill conditioned at
any point x ∈ R, since even for x ≈ 0 we get
limx→ 0 Pf(x) = 1, - Although being well conditioned for x ≈ 0, we see that
limx→ 0 Q1(x) = + ∞; limx→ 0 Q2(x) = − ∞
Definition: Consider an algorithmo that uses m elementary functions to calculate the function value z=f(x), in a FP(β,n) system. The expression for the relative error is linearly approximated by
| δzm ≈ Pf(x) δx + Q1(x)δarr1 + ... + Qm(x)δarrm |
| limx→ w |Pf(x)| = ∞ or limx→ w |Qk(x)| = ∞ (for some k) |
- We present the definition for one variable, but it is clear the generalization for algorithms that depend on a larger number of variables. For instance, for two variable functions we have the condition numbers Pf x(x,y) e Pf y(x,y).
Remark: An immediate consequence of the definiton is that ill conditioning implies numerical instability.
Assim, se é impossível resolver os problemas de mau condicionamento, sem mudar o número n no sistema FP(β,n) (o que pode ser feito em linguagens mais sofisticadas, como o Mathematica), devemos procurar evitar os problemas de instabilidade numérica, no cálculo de funçőes bem condicionadas. Isso pode ser feito procurando algoritmos estáveis, ou pelo menos evitando introduzir instabilidades numéricas no algoritmo.
Examples:
- Consider an algorithm to calculate f(x)=(x-1)2+1:
z1 = x-1; z2 = x+1; z3 = z1z2; z4 = z3+1; δf(x) ≈ 2δx. δf(x) ≈ 2δx + (1 − x-2) (δarr1 + δarr2 + δarr3) + δarr4
In fact, we may check that in any FP(10,n) system with rounding, if x=10-n-1 we get z1 = -1; z2 = 1; and therefore z4 = 0, giving 100% relative error, i.e. |δz4|=1 (even considering that x is exact and δx=0). For that FP system we know that the rounding unit verifies|δarr| < u = 0.5 × 101-n, - Recovering the hyperbolic sinus example, that function presents no
ill conditioning problems (for fixed x ∈ R),
but when x ≈ 0 the algorithm presents numerical instabilities, that
we see in the infinite limits for Q1 and Q2.
Based on the Taylor expansion, we may present an approximation that avoids that problem near zero. Thus,sinh(x)=(ex − e-x)/2 = (1+x+x2/2+O(x3) − (1 − x+x2/2+O(x3)))/2 = x+O(x3)
That error is neglectable for |x| < 10t in a FP(10,n) system when t < -n/3.
Therefore we may propose a stable algorithm to calculate z=sinh(x):- if t < -n/3 then z=x;
- if t ≥ -n/3 then z=z4 (using the sinh algorithm for z4);
Nonlinear scalar equations
However, no closed formula for third degree equations was found in the next millenia. Some advances made by medieval scholars (e.g. Fibonacci) were only completed in the XVI century, with the Italian Renaissance.
Afterwards, new difficulties and impossibilities for higher degree equations lead to numerical methods for the resolution of any equation.
These numerical methods also showed a performance that was better than the use of the closed formulas and it was not restricted to algebraic equations.
Algebraic Equations
- 1st Degree:
First degree equations have a trivial solution:
a x + b = 0 ⇔ x = -a-1 b (quando a ≠ 0)
While writing the solution in the form x = -a-1 b, we consider a general case, that includes matrices, if the condition a ≠ 0, is understood as the invertibility condition, det(a) ≠ 0. - Quadratic equation (2nd degree):
Second degree equations have a closed simple formula:
a x2 + b x + c = 0 ⇔ x = (2a)-1 ( - b ± (b2 − 4ac)1/2 ) (quando a ≠ 0)
This expression includes a solution in any field structure:
To solve x2 − x − 1 = 0 in Z7:
x = (2)-1 (1 ± (1 + 4)1/2) = 4 ( 1 ± 3 i) = 4 ± 2 i - Cubic and Quartic (3rd and 4th degree):
After the work of Khayyam
and other slow medieval advances,
del Ferro and
Tartaglia
found the formula to solve the cubic equation in the beginning of the XVI century.
These works were further explored to solve the quartic equation by
G. Cardan and
L. Ferrari
and published by Cardan.
Links to these formulas may be found here: cubic formula , quartic formula. These techniques developed at Bologna University failed during the next centuries to solve the quintic (5th degree). - Quintic (5th degree):
One of the most important problems in the next three centuries was to
prove or disprove the existence of a closed formula for the quintic.
After some substancial progresses by
Lagrange,
the non existence was proven independently in the begining of the XIX century by
Galois and
Abel.
This impossibility answer made it clear that there would be no way to express explicitly the solution of some algebraic equations with degree ≥ 5. - Degree p: Despite the non existence of an explicit formula for the quintic (or higher degree equations) it was analytically established (by Argand, Gauss, early XIX century) that any algebraic equation with degree p would have exactly p complex roots − it is the well known fundamental theorem of algebra.
Numerical Methods for Root Finding
Since explicit formulas were not available, even in the medieval times some numerical procedures were attempted. Fibonacci (XIII century) presents fixed point iterations to solve some specific algebraic equations, but he does not explore the method.
It was only in the XVII century, with the development of calculus in Europe, that numerical methods were clearly established, specially after the works of Newton (see also Raphson). The Newton Method that we will study is probably the most well known general method for root finding.
Rootfinding − general setting:
Given a real function f ∈ C[a,b], we want to approximate the solution z ∈ [a,b] verifying
| f ( z ) = 0 |
- The iterative methods consist in finding a sequence (xn) that converges to the solution z. This sequence is constructed in a recursive (or iterative) way, starting with some initial values and calculating xn+1 from the previous xn (or more xn, xn-1, ...).
- We note that once we establish the convergence of the sequence (xn) we have not only an approximation in each term xn, but also an exact representative of the real number through the convergent sequence of rational numbers (if xn are real, we can always consider a similar rational number that does not interfere in the convergence - the usual way is by rounding the decimals).
-
The methods presented in this chapter are mainly to find the roots
of an equation with a single real variable, but they may be used in
more general contexts − systems, functional or differential equations
(bissection is mostly restricted to ordered structures;
fixed point, Newton and secant methods have been generalized to
equations in complexes, matrices, operators...)
\end{itemize
We start by reviewing some basic Calculus results that ensure uniqueness and existence of solution in an interval (these are non constructive results).
Root localization
Theorem (Bolzano's (intermediate value) theorem : Existence ):
Let f ∈ C[a,b] : f(a) f(b) ≤ 0. Then ∃ z ∈ [a,b] : f(z) = 0.
BolzanoTheorem[f ∈ C[a,b] , f(a) f(b) ≤ 0] :: z ∈ [a,b] : f(z) = 0
The intermediate value theorem only ensures existence, to ensure uniqueness we may use:
Theorem (Rolle's theorem : Uniqueness) :
Let f ∈ C1 [a,b], f(a)=f(b) implies ∃ ξ ∈ [a,b] : f ' (ξ) = 0.
Thus, if f ' ≠ 0 then f is injective, and there exists at most one zero of f in the interval.
Lagrange's mean value theorem is a simple consequence of Rolle's theorem and leads to an a posteriori error estimate for any approximation.
Theorem (Lagrange's mean value theorem):
Let f ∈ C1 [a,b]. Then ∃ ξ ∈ [a,b]: f(a)-f(b) = f '(ξ) (a-b)
Corollary (Lagrange error estimate − a posteriori):
Let f ∈ C1 [a,b] with f '(x) ≠ 0 ∀ x∈ [a,b].
If z~ is an approximation of the root z ∈ [a,b], then
|
proof of the theorem:
Take g(x) = (b − a)f(x) − (f(b) − f(a))x.
We have g(a)= proof of the corollary:
Since z , z~∈ [a,b] there exists ξ∈ [z; z~ ] ⊆ [a,b]:
| f(z~) − f(z) = f '(ξ)(z~ − z) |
| |z − z~| ≤ |f(z~)| / minx∈[a,b] |f '(x)|. |
These theorems do not give any method to approximate the root. Nevertheless we may use the Intermediate value theorem to develop a very simple iterative method.
Bissection Method
We generate intervals [ an, bn ] half size of the previous ones [ an-1, bn-1 ], where we ensure the existence of the root, using the Intermediate value theorem.
The method by set with this algorithm :
- Initial interval :
| en = z − xn. |
| |en| ≤ |f(xn)| / minx∈[an-1, bn-1] |f '(x)| , |
- A priori estimate in the bissection method.
As xn is the middle point, the new interval [ an, bn ] is half size the previous one [ an-1, bn-1 ], meaning|an − bn| = ˝|an-1 − bn-1 | |an − bn| = (˝)n|a0 − b0 | = 2-n|a − b| . |en| = |z − xn| ≤ |an − bn| = 2-n|a − b| . - If we want that
|en| ≤ ε it is enough to demand2-n|a − b| ≤ ε ⇔ |a − b| / ε ≤ 2n
⇔ n ≥ log 2 ( |a − b| / ε )
We conclude, for instance, that for an interval |a − b|=1, double precision is ensured after a little more than fifty iterations, because to have ε < 2-56≈ 1.4× 10-17 it is enough that n > 56.
Fixed point method
| f(z)=0 ⇔ z=g(z) |
- Given any initial
Examples:
-
In a calculator machine, starting with 0 (or any other value), if we
repeatedly press the COS key, we obtain a sequence of values (in radians)
0; 1.0 ; 0.54… ; 0.857… ; ... ; 0.737… ; ... ; 0.73907… ; ... ; 0.7390851… ; etc... -
In this process we are aplying the fixed point method, and the iterative
function is the cosine function.
Starting with
-
In this process we are aplying the fixed point method, and the iterative
function is the cosine function.
| cos (xn)→ cos (z) |
| xn+1= cos (xn) → z = cos (z). |
| f(x) = 0 ⇔ x = g(x) = cos (x). |
| f(0) = 0 − cos(0) = -1 < 0, f(1) = 1 − cos(1) > 0 |
| minx∈[0,1] |f '(x)| = minx∈[0,1] |1+ sin (x)| = 1 |
| |z − 0.7390851…| ≤ |0.7390851… − cos (0.7390851…)|/1 = 0.55…× 10-7 |
As a counterpart, if you have a SQR (square) key you are considering g(x)=x2 and the sequence xn+1=xn2 converges to a solution of z=z2, which is z=0 when you start with |x0| < 1. If we start with |x0| > 1 the sequence goes to infinity. The iteration only gets the other solution z=1 when we start exactly with x0=± 1.
From this examples we saw different situations, leading to convergence and non convergence, that we will analyze.
Generally, the "key" that you repeatedly press is the iterative function g. The value with which you start is the initial iterate, and the sequence of iterations is obtained by "pressing the key". We may get a rough idea of convergence by checking that the decimal digits are stabilizing, but this may be misleading in some unclear situations.
Remark: No matter there is convergence or not, at each iterate you may evaluate its accuracy using the a posteriori estimate with f(x)= x − g(x) e z~=xn:
| |z − xn| ≤ | | xn − g(xn)| minx∈[a,b]|1 − g'(x)| | ≤ | | xn+1 − xn| 1 − maxx∈[a,b]|g'(x)| |
Based on general plots for different iterative functions g that we present in Fig. 1, we follow the iterations for convergence and non convergence ("divergence") situations.
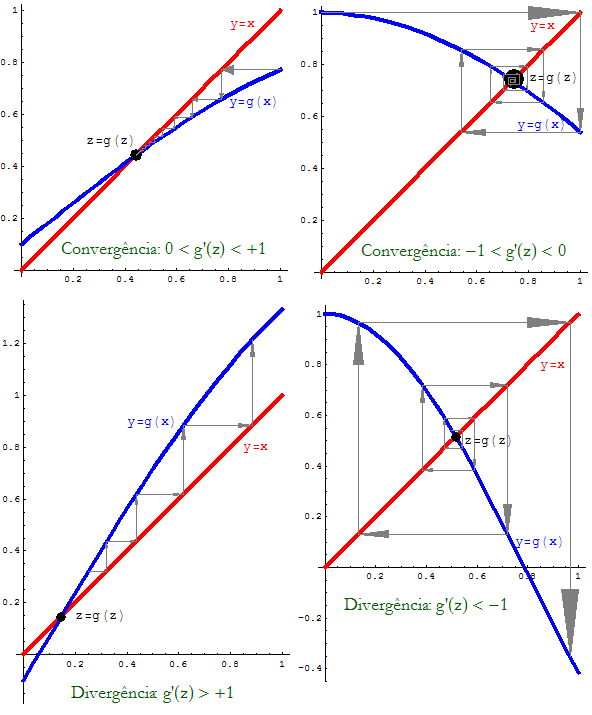
Figura 1: Fixed Point Method − different cases.
Definition:
We say that g is a lipschitzian function in [a, b] if there exists L > 0 such that :
| | g(x) − g(y) | < L | x − y | , ∀ x, y ∈ [a, b] |
Note that lipschitzian functions are continuous on the interval
(x→ y implies immediately g(x)→ g(y)).
When the function has derivatives we relate this notion to the bounds of the derivative:
Proposiçăo:
Let g ∈ C1[a, b] such that |g '(x)| ≤ L, ∀ x ∈ [a, b], then the function g is lipschitzian in that interval, and when L < 1 it is a contraction.
dem:
Using Lagrange's theorem, for any x, y in [a,b], there exists ξ ∈ ]x; y[ ⊂ [a, b] such that
| | g(x) − g(y) | = |g'(ξ)| |x-y| ≤ L |x − y|. |
With these notions we may now present a fixed point theorem (here only for an interval).
Theorem (fixed point in a bounded interval).
Let g be an iterative function in [a, b] such that:
- (a posteriori)
- (i)
- (iii)
When g∈ C1[a,b], L = maxx∈ [a,b] |g'(x)| < 1.
proof:
- Existence (fixed point in an interval):
it may be seen as simple consequence of the intermediate value theorem.
Take
Therefore, f(a)f(b)≤ 0 and there exists z∈ [a,b]: f(z)=0 ⇔ z=g(z).
Suppose
Using the contraction hypothesis
| |z − w| = |g(z) − g(w)| ≤ L |z − w| ⇔ (1-L)|z − w|≤ 0 |
Using the contraction hypothesis,
| |en|=|z − xn| = |g(z)-g(xn-1)| ≤ L |z-xn-1| = L |en-1| |
| |en| ≤ Ln |e0|. |
Finally (ii) results from
| |en|≤ L|en-1| = L|z − xn + xn − xn-1| ≤ L|en| + L|xn − xn-1| |
Also, (ii) implies |e1| ≤ L/(1 − L) |x1 − x0| considering n=1, and (iv) results from
|en| ≤ Ln-1 |e1|.
Proposiçăo:
Under the hypothesis of the fixed point theorem, we have:
- (a) If
(all iterations are on the same side: xn > z or xn < z)
(iterations change side at each step: xnxn+1 < 0)
dem:
As
| en = g(z) − g(xn-1) = g '(ξn) en-1 |
| sign(en ) = sign( g '(ξn) ) sign(en-1 ) |
in case (a): sign(en ) = + sign(en-1 ) = ... = sign(e0 ),
in case (b): sign(en ) = − sign(en-1 ) = ... = (-1)n sign(e0 ).
For instance, assuming that -1 < g' < 0 and it is monotone, after p iterations we define a new
|
Lp = max { -g '(xp-1); -g'(xp) }
|
|
|ep+k| ≤ (Lp)k | xp-1 − xp |
|
Example:
A method to solve quadratic equations x2+bx-a=0 consists in establishing the equivalence (for x≠ -b)
| x2+bx-a=0 ⇔ x(x+b) = a ⇔ x = a/(x+b) |
This leads to a sequence known as continued fraction
| xn+1 = a/(b+xn) = a/(b + a/(b + a/(b + ...))) |
For instance, for a= b= 1, starting with x0=1 we get
| x1=1/2, x2=2/3, ..., x6=13/21, ..., x13=377/610, x14=610/987, ... |
We may check that in the interval I=[1/2, 1] the fixed point theorem hypothesis are verified:
- contractivity:
| L = maxx ∈ I |g'(x)|= max{ -g'(1/2), -g'(1) } = max{ 4/9, 1/4} = 4/9 < 1 |
| g(1/2) = 2/3 ∈ [1/2,1], g(1) = 1/2 ∈ [1/2,1] |
| |e14| ≤ L/(1-L) |x14-x13| = 4/5×0.166…10-5 < 0.133×10-5 |
| L14= max {|g'(x13)|, |g'(x14)| } = 0.381966… |
| |e14+k|≤ 0.382k (0.133×10-5) |
Theorem (Non convergence or "divergence"):
Let g∈ C1(Vz) where Vz is a neighborhood of the fixed point z.
If | g '(z) | > 1, the fixed point sequence never converges to z, except if xp=z (at some step p).
proof:
We saw, using Lagrange's theorem:
| en+1 = g '(ξn) en |
Since en ≠ 0 (as xn≠ z)
| |en+1| = |g '(ξn)| |en| > |en| |
This is a local result, that allows to conclude non convergence as long as we show that the derivate (in modulus) is greater than 1, in an interval that contains the fixed point.
As a counterpart we may establish a local convergence result. This result is slightly different from the fixed point theorem, as it does not demand invariance, but we need have an a priori location of the fixed point, as the initial iterate must be sufficiently close to it.
Theorem (Local convergence): Let g∈ C1(Vz) where Vz is a neighborhood of the fixed point z.
If | g '(z) | < 1, the fixed point sequence converges to z, when x0 is sufficiently close to z.
proof:
This result may be reduced to the fixed point theorem considering
| Wz = {x: |x − z| ≤ ε} |
| |g'(x)| < 1, ∀ x∈ Wz⊂ Vz , |
| |g(x) − z| = |g '(ξ)| |x − z | ≤ ε ⇐ g(x)∈ Wz |
Within convergence cases, there are sequences that converge more rapidly than others. Thus, it is appropriate to distinguish the order of convergence.
Definition Let (xn) be a sequence that converges to z.
We say that (xn) has order of convergence p with asymptotic coefficient Kp ≠ 0 if the following limit exists
| limn→∞ | |en+1| |en|p | = Kp ≠ 0 |
We distinguish 3 main classes of convergence:
- Superlinear (or Exponential): when
Note that if the limit is Kp=0 this means that the convergence is at least of order p, but then one should look for an higher p, to obtain the correct order of convergence.
Examples:
We present some examples that are not necessarily connected to the fixed point method.
(i) Let xn = αn with 0 < α < 1.
This sequence converges to z=0, and we have
| K1 = limn→∞ | |en+1| |en| | = limn→∞ | |αn+1| |αn| | = α ≠ 0 |
(ii) Let xn = αβ^n with 0 < α < 1 < β.
[note that xn = α^(β^n)
is different from (α^β)^n = α^(β n) ]
This sequence also converges to z=0, but we have
| K1 = limn→∞ | |en+1| |en| | = limn→∞ | |αβ^(n+1)| |αβ^n| | = limn→∞ | |(αβ^n)β| |αβ^n| | = limn→∞ (αβ^n)β-1 = 0 |
| Kβ = limn→∞ | |en+1| |en|β | = limn→∞ (αβ^n)β-β = 1 ≠ 0 |
(iii) Finally a logarithmic convergence result.
Take xn = n-b with b>0, that converges to z=0. As,
| K1 = limn→∞ | |en+1| |en| | = limn→∞ | |(n+1)-b| |n-b| | = limn→∞ (1+1/n)-b = 1-b = 1 |
Theorem (Fixed point method − order of convergence):
Let g∈ Cp(Vz) where Vz is a neighborhood of the fixed point z.
If g(p)(z)≠ 0, e g'(z) = ... = g(p-1)(z) = 0, then the (local) order of convergence of the fixed point sequence is p, and the asymptotic coefficient is given by
| Kp = |g(p)(z)| / p! |
proof: The local convergence was ensured in the previous theorem for K1 = |g'(z)| < 1.
Using the Taylor expansion with Lagrange remainder
| g(xn) = g(z) + g(p)(ξn)/p! (-en)p, com ξn ∈ [xn;z] |
On the other hand, g(xn)=xn+1 and z = g(z) means
| - en+1 = g(p)(ξn)/p! (-en)p, |
| Kp = limn→∞ | |en+1| |en|p | = limn→∞ |g(p)(ξn)|/p! = |g(p)(z)| / p! ≠ 0 |
Remark:
(i) It is an immediate consequence of the definition of order of convergence that if a method has order of convergence p > 1, a method grouping two iterations will have order of convergence 2p. Therefore, it is a qualitative difference to obtain superlinear convergence, and it is a secondary issue to obtain higher orders of convergence (despite some emphasis in the usual literature).
Furthermore, if the convergence is just linear, a new method grouping two iterations, will just reduce the asymptotic coefficient to one half.
Thus, the order of convergence plays a similar role to superlinear methods, as the role of the asymptotic coefficient in linear convergent methods.
(ii) Another possibility to define order of convergence p, consists in having a constant Kp > 0 such that
| |en+1| ≤ Kp |en|p (n sufficiently large) |
Furthermore, knowing the order of convergence, we may establish a relation between the difference of iterations and the absolute error:
| |en| = | |xn+1 − xn| |1 − en+1/en| | ≤ | |xn+1 − xn| 1 − Kp |en|p-1 |
| |en| ≤ | Kp |en-1|p-1 1 − Kp |en-1|p-1 | |xn − xn-1| |
Based on the difference of iterations we may define a stopping criteria, noticing that
|
Newton Method
When f '(x) ≠ 0 we may establish an equivalence
| f(x) = 0 ⇔ x = x − f(x)/f '(x) |
| g(x) = x − f(x)/f '(x). |
| g'(x) = f(x) f ''(x)/(f '(x))2 ⇒ g'(z) = 0 |
(it might be cubic, if f '(z) ≠ 0, f ''(z) = 0).
Newton Method consists in applying the fixed point method to this g, meaning
- Given an initial iterate
|
Remarks:
(1) Newton Method has also a geometrical interpretation that is related to its original deduction (this method is also called Newton-Raphson Method, or Tangent Method) as presented in Fig. 2.
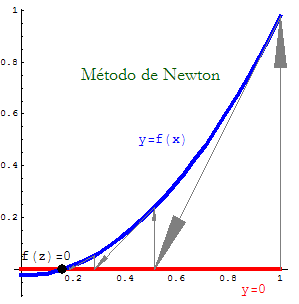
Figura 2: Iterations in Newton Method.
The geometrical deduction consists in using the tangent line
| y = f(xn) + f '(xn)(x-xn) |
| 0 = f(xn) + f '(xn)(x-xn) ⇔ x = xn − f(xn)/f '(xn) |
(2) We may be led to deduce higher approximations, increasing the order of the Taylor expansion. This leads to a higher order of convergence but also to more complex expressions, that are computationally less efficient than grouping iterations (see previous remarks).
In fact n iterations with Newton Method are usually more efficient than a single iteration with some other methods of order 2n.
Examples:
We present some examples that show the performance of Newton Method.
(i) Calculate z= p√ a using only arithmetical operations.
Note that here z is the solution of f(x) = xp − a = 0.
According to the local convergence theorem, we take a sufficiently close x0, and the method resumes to
| xn+1 = xn − (xnp-a)/(p xnp-1) = xn(1-1/p) + (a/p) xn1-p |
| xn+1 = xn/2 + a/(2 xn) |
(ii) Consider for instance the calculation of z= 3√ 6:
| x0 = 2, x1 = 11/6, x2 = 1.817263…, x3 = 1.81712060…, x4 = 1.817120592832139… |
(iii) Recovering the continued fraction example, the application of Newton Method to f(x)=x2+bx-a=0 leads to calculations that involve also simple fractions
| xn+1 = xn − ((xn+b)xn-a)/(2xn+b) = (xn2+a)/(2xn+b) |
| x1=2/3, x2=13/21, x3=610/987, x4=1346269/2178309, ... |
Again, we are also interested in establishing sufficient conditions that ensure a convergence that is not only local (for a "sufficiently close initial iterate"), but that is valid for a set of initial iterates in an interval.
Theorem (Convergence of Newton Method − sufficient conditions for an interval):
Let f∈ C2[a,b] such that in the interval (x ∈ [a, b])
- (1)
z ∈ [a,b], initializing the method:
- (a) with
proof:
A non constructive proof is simple but not relevant here, we prefer to discuss the conditions:
- Note that conditions 1) and 2) imply existence and uniqueness.
- Condition 3) is important such that the convexity does not change,
leading to a cyclic, non convergent situation:
− For instance, if
| x0 = 1, x1 = 1 − (1-5)/(3-5) = -1, x2 = 1, ..., xk = (-1)k, |
| x1 = a − f(a)/f '(a) ⇐ |x1 − a| = |f(a)/f '(a)| ≤ |b − a| |
Theorem (Newton Method − Error Estimates):
Let f∈ C2[a,b] and assume the previous quadratic convergence conditions. We have the following error formula:
| ∃ ξ ∈ [xn; z] : en+1 = − | f ''(ξ) 2 f '(xn) | (en)2 |
| K2 = | |f ''(z)| 2 |f '(z)| |
- (a posteriori)
|en| ≤ maxx∈ [a,b] |f ''(x)|
2 |f '(xn-1)||en-1|2 - (a priori)
M |en| ≤ (M|e0|)2^n M = maxx∈ [a,b] |f ''(x)|
2 minx∈ [a,b]|f '(x)|
proof:
− The Error Formula results from the Taylor expansion
| 0 = f(z) = f(xn) + f '(xn)(z-xn) + ˝f ''(ξn)(-en)2 |
| 0 = f(xn)/f '(xn) + z − xn + ˝f ''(ξn)/f '(xn)(en)2 |
| 0 = z − xn+1 + ˝f ''(ξn)/f '(xn)(en)2 |
− the first estimate is immediate, since ξ ∈ [xn; z]⊂ [a,b].
− the second estimate is also immediate, as
| M |en| ≤ (M|en-1|)2 |
Remarks:
(i) When f '(z)=0 we are in the situation of a double root (at least), and Newton Method loses quadratic convergence, being possible a slight change to recover quadratic convergence (e.g. [CA]).
(ii) When f ''(z)=0 (and f'(z) ≠ 0) we obtain a cubic convergence.
(iii) As an empirical rule quadratic convergence means doubling the number of significant digits in each iterate (... cubic convergence means the triple). This means that near the root, double precision exact value is achieved in less than 4 or 5 iterations, being more important to get there in the first place.
(iv) We stress this point, as it follows from the error estimates that to have an acceptable a priori estimate the value M|e0| should be less than 1, and this means that the initial iterate should not be far from the solution (moreover if |f '| is small or |f ''| is large).
Example:
Consider f(x)= e-x − log(x) = 0, that verifies in the interval [1,2]:
- 1)
Since |f(1)/f '(1)| = 0.2689… , |f(2)/f '(2)| = 0.87798… < |2-1| = 1, following conclusion (b), we have convergence given any x0∈ [1,2].
Starting with x0=1 we get
| x1=1.2689…, x2=1.309108…, x3=1.3097993887… |
| |e3|≤ 2.04× 10-7 / 0.635 < 3.21× 10-7. |
Using this information we may improve the next estimates.
The interval is now small enough to consider M≈ K2 ≈ 0.413, therefore
| 0.412|ek+3| ≤ (M|e3|)2^k ≤ (1.325× 10-7)2^k |
| |e5|≤ 0.412-1(1.325× 10-7)4 < 10-27 |
Secant Method
Like the Newton Method, the Secant Method may be deduced in a geometrical way, substituting the tangent line by a secant line.
Given two points xn-1 and xn we define the "secant line" that crosses the image points:
| y = f(xn) + | f(xn) − f(xn-1) xn − xn-1 | (x − xn) |
In a similar way, solving for y=0 we get
| x = xn − | xn − xn-1 f(xn) − f(xn-1) | f(xn) |
Resuming, Secant Method consists in
- Defining two initial iterates
|
Error Formula (Secant Method)
It is possible to establish the following formula (check details in [KA])
| ∃ ξn, ηn ∈ [xn-1; xn; z] : en+1 = − | f ''(ξn) 2 f '(ηn) | en en-1 |
|
| limn→∞ | |en+1| |en| | = limn→∞ | |f ''(ξn)| 2 |f '(ηn)| | |en-1| = | |f ''(z)| 2 |f '(z)| | limn→∞ |en-1| = 0 |
It may be shown (e.g. [KA]) that if f '(z) ≠ 0 the order of convergence of Secant Method is p=(1+√ 5)/2 = 1.618… the golden number.
NOTE: In fact, taking yn = log|en| and applying logarithms to the formula, we establish (hand waive argument)
Theorem (Convergence of the Secant Method − sufficient conditions in an interval)
Let f ∈ C2[a,b]. In the hypothesis (1), (2), (3), of the similar theorem for Newton Method, Secant method has a superlinear order of convergence p = 1.618…, initializing
- (a) with
Example:
Consider again f(x)= e-x-log(x) = 0 the conditions (1), (2), (3) were already verified in [1,2]. As the condition (b) was also verified, we may use any pair of initial iterates to obtain with the Secant Method a sequence with superlinear convergence.
Starting with x-1=1, x0=1.5, we get
| x5=1.309799585804… com |e5|≤ |f(x5)|/0.635 < 2× 10-13 |
Final Remarks and References
[CA] C. J. S. Alves, Fundamentos de Análise Numérica (I), Secçăo de Folhas AEIST (2002).
[KA] K. Atkinson: An Introduction to Numerical Analysis, Wiley (1989)